Thursday, April 6. 2006Version 1.8.2 Released
You can download the 1.8.2 version. The user interface has become much more mature:
 The areas which have been improved most are related to the text box and text line object. The text styles can be applied directly from the ribbon, by choosing in a gallery of available styles. The same is true for the fonts. If you need to define your own styles, simply click on the styles tab, then select either the paragraph or the character style sub-tab and copy/modify or create your styles. I've also added support for WMF/EMF (Windows Metafiles) import. Selecting such an image when drawing an image object will work; internally, the image is converted to a bitmap with the WMF/EMF specified DPI resolution. This can lead to jaggy images when printing. As always, please let me know if something does not work properly for you. Thanks! Saturday, March 18. 2006Version 1.8.1 ReleaseTuesday, March 14. 2006Version 1.8.0 Released
This release fixes quite a few bugs (and possibly adds a few new ones
 ) as we finally added a panel to edit the properties for bullets and numbering. ) as we finally added a panel to edit the properties for bullets and numbering.You can download the 1.8.0 version and give it a try: 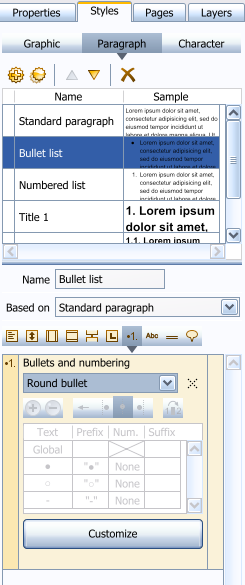 You can choose from a list of predefined numbering styles. If none fits your needs, simply pick the one which looks most what you'd like to get and click on the Customize button: 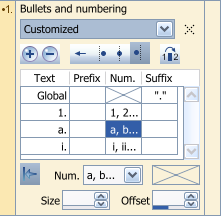 In this example, the first level is numbered as 1., 2., 3., etc. The second level is numbered alphabetically a., b., c., etc. The third level is numbered with roman digits i., ii., iii., etc. In this case, every level has been set to be independent from the previous levels, which will be useful to create multi-level lists (left-hand side of following example). You could also have defined a numbering applied to titles, in which case every level keeps the numbering of the previous level and appends to it. Clearing the arrow button (bottom left of the panel, titled Override former levels) for every level would produce the right-hand side of this example:  Hint: If you want to create documents with predifined text styles, you should open the settings (F5), switch to the Global settings, General tab, and define a template such as normal.crmod which is installed in the Samples folder usually located in c:\Program Files\Creative Docs .NET. Thursday, February 23. 2006Version 1.7.0 BETA released
After a long month of silence, we have finished the implementation of the text styles. Ready internally since fall 2005, the text style proved a real challenge to make them easy to define and use in the GUI. We wanted both something rich (to benefit from our powerful text engine) yet not too different from what Microsoft Word users expect.
If you try out the 1.7.0 version, you will notice that we have provided you with a few default styles: 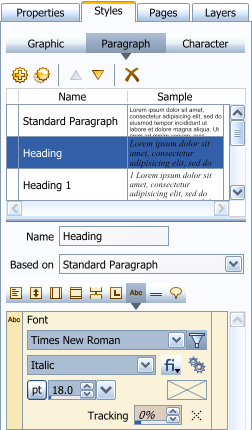 The numbered styles cannot be edited (yet) as we are still working on the bullets and numbering pannel. But you can already try them out if you want.  To change the level in a list, use the indentation buttons, found in the ribbon:  Other changes
Friday, January 13. 2006Version 1.6.1 Release (small fix)Thursday, January 12. 2006Version 1.6.0 released
We are excited to announce this new release available here, which includes an object which was missing in version 1.5.0, the text line. It is a very flexible object indeed:
 Since the text engine is the same for the text line than for the text box, you have access to very rich functionality. The text line is in no way a cripple  Other improvements include:
Sunday, January 8. 2006Memory useThursday, January 5. 2006Why we use .NET instead of Win32
Karl asked why we used .NET and not standard C++ against the raw Win32 API to write our framework. He moreover observes that a freshly started Creative Docs .NET instance uses 240MB on his machine and takes 30 seconds to launch... That's a lot and reflects typical values for pre 1.5 versions (more on that below).
My own measurements show that version 1.5 has a working set of about 90MB and that .NET heaps account for about 17MB reserved bytes (33MB reserved). 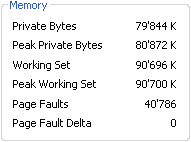 But back to the original question: why .NET and not just C++/Win32 for the framework? More than 10 years ago I started working on a portable GUI toolkit (visit OPaC historic web site), which only required very minimal support from the underlying operating system. All the drawing was done internally using a home-made 2D graphics engine, with alpha transparency support. The memory was tracked by a custom garbage collector, which relied on C++ wrapped pointers and reference counting; it was also able to properly handle cycles in complex graphs and I was very proud of it. Serialization and deserialization of object instances was automatic and did not require explicit support. This was all nice and fun, but tedious to implement and maintain. There were tons of macros which provided something similar to runtime introspection (what .NET calls reflection) to support all the framework magic. The project went through several major changes in order to keep up with my ideas of improvements. But then, Microsoft announced the .NET platform. I was stunned: they had just developed the whole infrastructure and language (CLR and C#) which I was trying to painfully build in pure C++. It was both a dream coming true and an uncredible nightmare: I could either switch to .NET and benefit from the huge work done by Microsoft or continue to work with my own C++ code, and stay back from the big move. I did some quick performance tests and was very surprised to discover that .NET was in most areas about as fast as what I had implemented in OPaC, or even faster, so the choice finally proved easy (yet, trashing a few hundred thousand lines of code remained painful). Switching to .NET was a sensible choice. I lost some control on the low level code, but this is far outweighted by the advantages offered by the CLR/C# duo. The working set has increased (the number of DLLs required to run even a very simple .NET application is high) but this should not be dramatical as memory prices continue to fall. What's 100MB of RAM today, anyway? For those who are interested in seeing what kind of application could be achieved with the old OPaC framework (on Win32), download an ancestor of Creative Docs .NET, named PAGE, here. It works only on 16bpp displays, so be sure to configure your display to 65,536 colors before launching it... Saturday, December 24. 2005Version 1.5.0 released for Christmas
We are glad to announce the release of version 1.5.0. It is the first non-beta release since we replaced the text engine in Creative Docs .NET. Download version 1.5.0 here and please report problems by placing a comment in this blog or send a message to bugs [at] creativedocs.net.
There are a few improvements over 1.4.9, most notably:
Wednesday, December 21. 2005Version 1.4.9 BETA released
We are still working on the Christmas release (which will be tagged 1.5.0) but we felt that the current internal version 1.4.9 was stable enough to be released as a new BETA version. Download version 1.4.9 here and please report problems by placing a comment in this blog or send mail to bugs [at] creativedocs.net.
Here are a few highlights for this release:
Warning: in this version, you can no longer edit texts created in the previous releases. This is a breaking change! Wednesday, December 14. 2005Some progress report, at lastThursday, November 17. 2005Congratulations to Paint.net
A few days ago, Paint.net reached 1 million downloads. That's properly amazing! I wonder how long it will take for Creative Docs .NET to reach this kind of exposure.
So please, keep downloading it
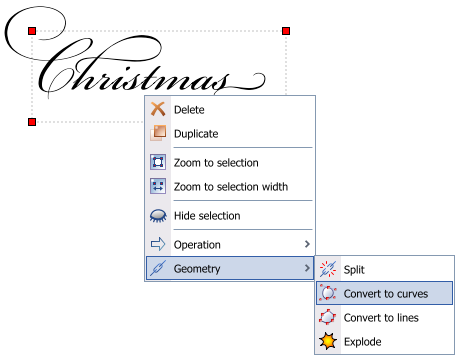
Tuesday, November 1. 2005Fancy fonts
Here is a demo of what can be done when using the Bickham Script Pro font in the experimental text object:
 This font defines tons of typographic alternates for the glyphs. The lower case letter "f", for instance, has 8 different shapes. Applications such as Adobe InDesign are smart enough to select automatically the proper alternate, based on information found in the GSUB table. Sunday, October 30. 2005Text II, part 2
In the Common.Text project (Text II, part 1), the text is stored internally as 64-bit character codes (ulong in C#). At first, using 64 bits to store a single character may seem foolish, as most western languages would be perfectly happy with an 8-bit encoding. Since .NET uses 16-bit character codes to represent Unicode text, 16-bit (char) should have been the logical choice for an internationally oriented piece of software.
However, 16 bits are not enough to cover the full Unicode range without using surrogate pairs for the codes above U+FFFF. In UTF-16, these codes are represented using a high-surrogate code (in the range U+D800 to U+DBFF) and a low-surrogate code (in the range U+DC00 to U+DFFF); together, this pair provides 20 bits of useful information, which is used to map the codes from U+10000 to U+10FFFF. Having to deal with the surrogate pairs is just a pain in the neck, and I wanted to get rid of them in order to have a one-to-one mapping between the cursor position to the character offset. So I chose to use at least 21 bits to store a character code (which currently covers the whole defined Unicode range). So why not use the next natural size (24 bits or 32 bits)? Simply because I also wanted to attach to every character its complete formatting information, plus some status flags which would allow me to decide very quickly if a piece of text belongs to the active selection, or not. I settled to the following internal representation:  As you can see, the formatting information is stored in three chunks, in the top 7+7+18 bits. Then come 5 bits used as markers (flags), 3 bits used to cache the results of a line break analysis, 3 bits to store Unicode related flags and 21 bits for the full Unicode character code. The formatting information has been split in three in order to speed up the layout analysis. The style index is used as an index into a table which stores font and font geometry related information. The local settings index and the extra settings index are used as indexes into subtables, which store information such as a glyph replacement code, an image name, a link target, a language or a color. With this setup, characters which share the same font face, font style and font size also share the same style index. Therefore, when analysing a piece of text with a given style index, the layout engine only needs to look up the formatting information once, even if the characters have different colors. Wednesday, October 12. 2005Text II, part 1 |
Calendar
QuicksearchCategoriesSyndicate This BlogBlog Administration |
|||||||||||||||||||||||||||||||||||||||||||||||||